Finding Spotify's top 500 artists
When You Take a Game Too Seriously
Here’s a fun game for you - try to find the top 10 artists on Spotify.
To find out an artist’s ranking, head over to his profile on Spotify and look for a badge in the ‘About’ section. If he is in the top 500, there will be a badge.
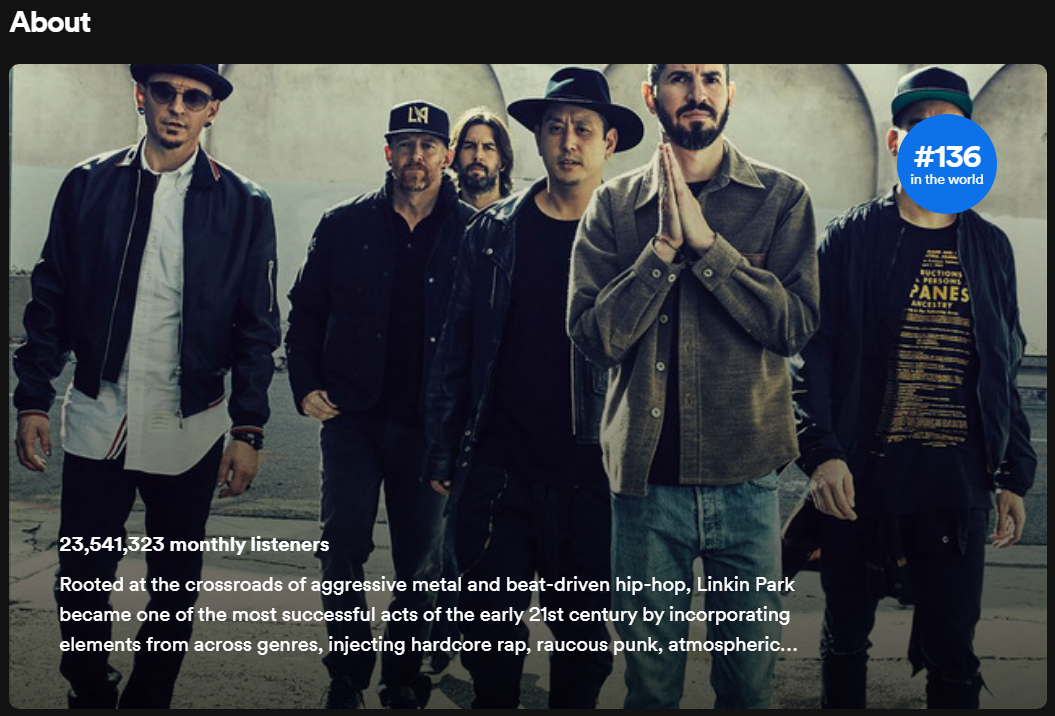
Linkin Park still holding on to #136
No, really, try and find them. Or instead, do it with friends. Success is very rewarding in this game as there is no way to cheat. At the time of writing, a public list does not exist, nor does an API endpoint by Spotify.
I was introduced to this game by a friend at work. Our team got instantly hooked. Top 10 wasn’t enough. We looked for the top 20, and once we found them, we turned to the top 30. Our appetite for ranking couldn’t be satisfied, so we took upon ourselves the terrible quest of finding the last on the list, number 500. This is harder than it may seem. You see, at this part of the list the ranking changes frequently. As if it’s not hard enough to find the right artist, once you have it - it’s gone.
We managed to find artist 500 several times. We also tracked the top artists and witnessed their ranking change as albums were released and as time progressed. But all good things come to an end. My co-worker’s motivation declined and shifted to other shenanigans. However, I still had an itch. A dream, if you’d call it. I wanted to have them all.
And so, the quest for the 500 has begun.
Method #1 - Scraping
The first method that came into my mind was scraping. I could collect artists by scraping playlists and the ‘Fans also like’ section in artist’s profiles. So I sat with B, a good friend of mine, and we wrote a Python script that does just that.
The main hurdle was retrieving the ranking from an artist’s page. Artist’s rank appears on Spotify’s web player only after some rendering. We used Requests-HTML, which renders with Chromium. The rendering was quite unstable. Sometimes it wouldn’t work, depending on the internet speed and load on the CPU. After tweaking the settings a bit we settled on a timeout of 20 seconds inside a while loop, and used the number of links found as a criteria of a successful render.
while len(found_links) < 10:
try:
r.html.render(timeout=20, scrolldown=20)
except Exception:
pass
found_links = r.html.links
The ranking is determined by the number of monthly listeners. Number 500 at the time [Milky Chance] had around 10,500,000. We didn’t scrape for artists when the current one had less than a million monthly listeners to keep ourselves out of indie scenes. Here’s the code that collects the data from a profile. Note the HTML classes:
monthly_listeners = int(r.html.find('.Ydwa1P5GkCggtLlSvphs', first=True).text.split(' ')[0].replace(',',''))
if monthly_listeners > 1000000:
for link in found_links:
check_link(link)
rank_elements = r.html.find('.hOGXfw')
rank_element = next((elem for elem in rank_elements if elem.text and elem.text.startswith('#')), None)
rank = int(rank_element.text.split('#')[1]) if rank_element else None
artist_name = r.html.find('.hVBZRJ', first=True).text
We ran the script, and artists started to pile up. But eventually, this method [or rather our implementation of this method] didn’t prove itself for two reasons.
- The rendering was too slow.
- We didn’t handle the sessions correctly, and in time my laptop found itself running tens of
Chrome.exeinstances.
Chromium Hell
Method #2 - Cross-Referencing
A week later I talked about what happened with Reuven, another good friend of mine. He immediately presented me with another solution - cross-referencing Spotify with a “top artists” list from a different platform.
I met again with B. This time we wrote the script with node.
The first step was to find an accurate “top artists” list. Last.fm was an obvious choice as its main purpose is collecting and presenting music streaming data. And indeed, they had just the correct endpoint, chart.getTopArtists.
Sounds too good to be true? It is. The endpoint was surprisingly unstable. Notable examples include:
page2 will return pages 1 and 2page14 will return 28 results instead of 50limitof 200 will return 50limitof 1000 will return small and irrelevant artists- Some artists appear on the list several times
Still, this is probably the most reliable source for music streaming data.
The second step is to translate the information returned by Last.fm to Spotify. The information Last.fm returns for an artist looks like this:
{"name":"The Weeknd","playcount":"313693094","listeners":"2685014","mbid":"c8b03190-306c-4120-bb0b-6f2ebfc06ea9","url":"https://www.last.fm/music/The+Weeknd","streamable":"0","image":[...]}
At this point I was thinking to use mbid to find the artist on Spotify. To quote MusicBrainz:
One of MusicBrainz’ aims is to be the universal lingua franca for music by providing a reliable and unambiguous form of music identification; this music identification is performed through the use of MusicBrainz Identifiers (MBIDs).
The problem was Spotify uses a different system of identification, and both MusicBrainz and Spotify don’t hold references to each other. The Echo Nest had the ‘Rosetta Stone’ project which did just that until they were absorbed by Spotify in 2014.
With mbid out of the way, I decided to use the name of the artists directly. Spotify’s API has the search endpoint which is used by the search feature in the UI.
Here’s a snippet from our code that maps an array of artist’s names to an array of objects with Spotify artist ID:
const requests = names.map(artist_name => {
return fetch(`https://api.spotify.com/v1/search?type=artist&limit=1&q=${encodeURIComponent(artist_name)}`, options)
.then(response => {
if (!response.ok) {
throw Error(response.statusText);
}
return response.json();
})
.then(data => {
return {"name": data.artists.items[0].name, "id": data.artists.items[0].id};
})
.catch(err => console.log(err));
});
return await Promise.all(requests);
The third and last step is to find the artist’s ranking. Reuven found the undocumented endpoint used by the Spotify web player to get an artist’s information, so there was no need for rendering this time. Here’s an example of using the endpoint [Notice uri and sha256Hash alter between requests, and an Authorization header needs to be specified]:
https://api-partner.spotify.com/pathfinder/v1/query?operationName=queryArtistOverview&variables={"uri":"spotify:artist:7k29FbDq69ju2fe6zTskxY"}&extensions={"persistedQuery":{"version":1,"sha256Hash":"433e28d1e949372d3ca3aa6c47975cff428b5dc37b12f5325d9213accadf770a"}}
This request returned all that was needed, including worldRank and monthlyListeners.
With everything set, we ran the script. The pace was good. I couldn’t wait to get hold of all the 500.
To my genuine surprise, some of Spotify’s top 500 didn’t appear in Last.fm’s 10,000 list. In despair, I cross-referenced other lists [ChartMasters Spotify most streamed artists and RollingStone 500 Artists], but new artists were bearly found. With all the results combined [Together with scraping] five artists were still missing.
Method #3 - Asking For Help
At this point, I lost my composure and decided to contact Spotify’s Support.
You can guess how this conversation went on.
I posted on Spotify Community and Reddit asking for help in finding the missing five, hoping that using the wisdom of the crowd I’ll be able to find them. Little did I know there was no need for a crowd. All I needed was one Redditor.
u/Riskyyy single-handedly found all the missing five. You can witness the action in this comment thread.

Finally, on the 10th of July 2022, I had them all.
Afterthought - The Ultimate Method
While writing this post I realized the ultimate method was actually hiding in plain sight. Spotify’s undocumented endpoint for artist information [that’s mentioned above] returns not only the ranking but also IDs of similar artists. With this data, I can crawl through Spotify without wasting time on rendering. This probably allows me to maintain the list automatically, without consulting Reddit ^_^